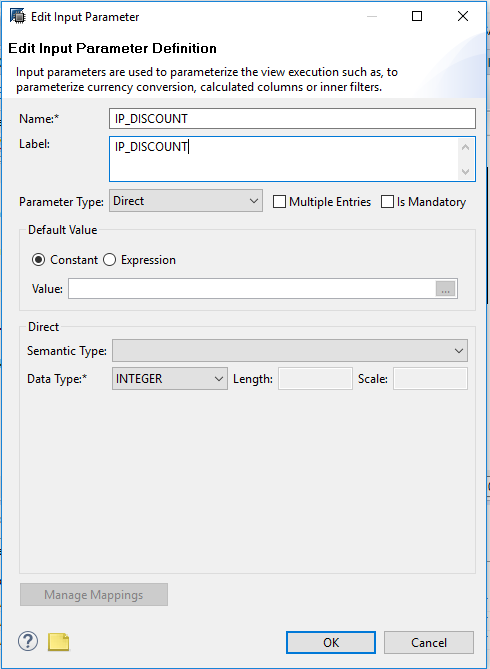
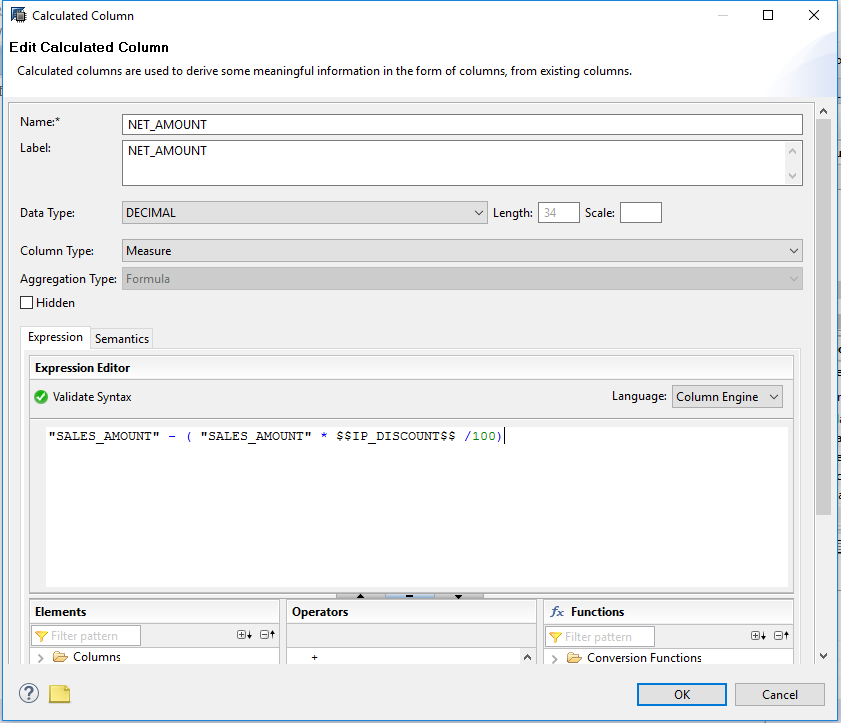
Calculation views are composite views that are used to calculate complex tabular results using either explicit SQL script code or a data flow graph that is visually created in the SAP HANA Studio.
It can consume other analytical/attribute/calculation views and tables. It can perform complex calculations that are not possible with other views.
The calculation views are of the following types:
• Graphical calculation views are created using the graphical editor
• Scripted calculation views are created using the SQL editor
Complex calculations, which are not possible through the graphical approach, can be created using SQL script.
Calculation views can be used in the same way as analytic views.
In contrast to analytic views, it is possible to join several fact tables in a calculation view where measures are selected from the different fact tables.
Following are general guidelines for deciding whether to use calculation views or analytic views:
• Use analytic views where mostly aggregation of data is required. These views perform very well on database selection of data, but the opportunities for transformations are limited.
• Use calculation views where more than one fact table needs to be combined and where complex calculations or other transformations are needed.
• For a simple union of analytic views, the graphical method is good.
• For complicated transformations, use the SQL method. Where possible, use the proprietary variant of the language called for, which, in this case, is SQL Script.
Graphical calculation views support the following types of calculation nodes:
Projection node
This node is used to define filters and select columns. Usually, you put each data source, such as an embedded table or view, into a projection node and apply a filter to cut down data size as early as possible.
Join node
This node is to define joins. If one table needs to join multiple tables, you need to join them one by one in separate nodes. Alternatively, you can create a star join node and then join from one table to multiple tables at one node.
With a star join, all the tables need to be wrapped into calculation views. Star joins are like analytic views except they allow you to create measures from different tables.
You can make inner joins, outer joins, referential joins, and text joins on a calculation view as well, but there is a limitation on text joins. The filter on the WHERE clause of a query will not be pushed down to the table level when there is a text join in the calculation view. If this causes performance issues, then you need to consider a different approach than using a text join.
On the join node, SAP HANA also supports the spatial join, which enables you to handle calculations between 2-D geometries performed using predicates, such as intersects, contains, and more.
Aggregation node
This node is used to define aggregation. You can define the aggregation type as SUM, MIN, MAX, or COUNT. You also can create a counter, which is used to calculate COUNT DISTINCT.
Union node
• Unions are used to combine the result set of two or more data sources.
• The funny fact about this UNION node here is that it doesn't work like a UNION.
• It works as a UNION ALL operator.
• This means that keeps piling one data set below the next without aggregating them.
Rank node
With a rank node, you can filter data based on rank.
This is the exact replacement for RANK function in SQL. We can define the partition and order by clause based on the requirement. You can set the SORT DIRECTION as DESCENDING (TOP N) Or ASCENDING (BOTTOM N).
The THRESHOLD field is to set the value of N. PARTITION BY COLUMN sets the columns to partition the records into multiple windows.
In each window, it returns the Top N or Bottom N records. The DYNAMIC PARTITION ELEMENTS checkbox allows you to choose the columns dynamically from the list under PARTITION BY COLUMN in case some of these columns do not exist in the query.